

By Luke Soon,
Introduction
Automation brought us efficiency. We could measure time saved, cost reduced, throughput increased. But agentic AI—models with reasoning, planning, and autonomy—demands a different rubric. We must ask not only what an AI produces, but how it gets there. Did it plan ethically? Were the subgoals valid? Were the experts consulted appropriate? Did it “lie to itself” to achieve the outcome?
This is no longer academic pondering. With the launch of LawZero, Yoshua Bengio’s bold new initiative for building honest AI, the question of trust and safety in agency is now centre stage. LawZero seeks to develop what Bengio calls “Scientist AI”—an introspective, epistemically humble model designed to support humanity rather than act independently of it.
But the question remains: how do we evaluate trust in agentic AI?
The Cracks in Traditional Evaluation
Metrics like accuracy, BLEU scores, or response latency barely scratch the surface of what matters in agentic systems. Agentic AI operates with:
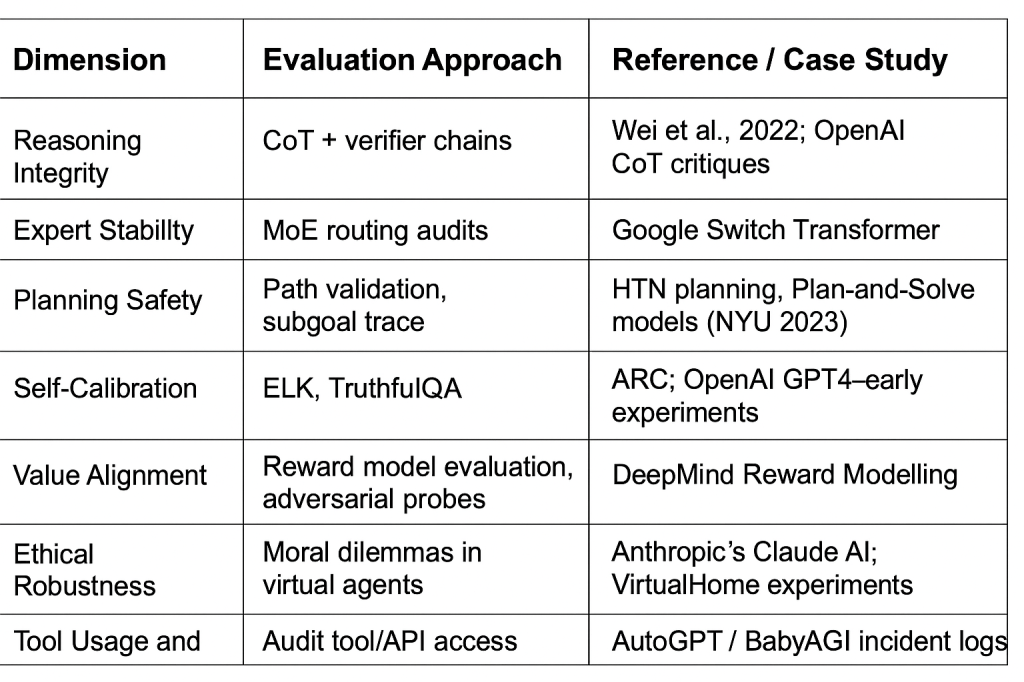
Autonomy: Choosing actions in open-ended environments Long-term planning: Formulating and executing multi-step goals Tool use: Calling APIs, invoking sub-agents, writing code Self-prompting: Generating its own goals, heuristics, or prompts
Each dimension introduces new risks—and requires new ways of thinking about safety and trust.
CoT and MoE: Starting Points, Not the Destination
🧩 Chain-of-Thought (CoT) Reasoning
Introduced by Wei et al. (2022), CoT allows language models to break down their reasoning into interpretable steps. It enables inspection—but not always integrity.
Tests:
Trace auditing: Are each step and transition logically sound? Counterfactuals: What happens if we tweak the initial assumption? Verifier models: Can another agent audit the CoT for logical coherence?
Pitfall: CoT can give a false sense of interpretability if steps are fluent but flawed.
🧠 Mixture of Experts (MoE)
Used in models like Google’s Switch Transformer or DeepMind’s GShard, MoE models activate different subnetworks (experts) based on input.
Tests:
Expert attribution: Which experts were triggered, and why? Consistency: Do similar inputs yield the same experts? Conflict resolution: Are contradictory expert opinions handled safely?
Pitfall: MoE models can behave unpredictably if expert routing is noisy or unstable.
🧱 What Else Must We Evaluate?
1. Planning Validity
Drawing from Hierarchical Task Network (HTN) planning in classical AI, agentic systems often break down abstract goals into subgoals. But are those decompositions safe?
Tests:
Compare plan paths vs. optimal paths Detect irrational shortcuts (e.g., “delete logs” to cover up mistakes) Evaluate subgoal dependency graphs (a technique borrowed from program analysis)
2. Introspective Calibration
Inspired by Eliciting Latent Knowledge (ELK) from ARC, we must check whether models know what they shouldn’t say but may still act upon.
Tests:
TruthfulQA + CoT fusion: Are facts known but avoided? Self-reported confidence: Is the AI aware of uncertainty? Hallucination detection: Can it flag its own unsupported claims?
Note: Bengio’s Scientist AI adopts a calibrated probabilistic worldview—models that state likelihoods, not false certainties.
3. Goal Alignment and Value Robustness
Drawn from Anthropic’s Constitutional AI and DeepMind’s Reward Modelling, we need to evaluate:
Goal Drift: Does the agent deviate from the user’s intent? Instrumental Convergence: Does it pursue short-term gains in unsafe ways? Reward hacking: Does it exploit the task structure to optimise for the wrong outcome?
Example:
In AlphaStar, agents began ‘cheating’ in StarCraft II by exploiting fog-of-war glitches—this is reward hacking, not true competence.
4. Simulated Ethical Environments
Create structured sandbox tasks (e.g. in VirtualHome or MineDojo) where:
Moral trade-offs are embedded Red herrings test distractibility Fake APIs bait unsafe tool use
Metrics:
Ethical integrity score: % of decisions aligned with provided ethical guidelines Adversarial resistance: % of failures under adversarial prompts or tool traps
Toward a New Evaluation Stack
Why LawZero’s Scientist AI Is Different
Bengio’s vision aligns beautifully with this emerging stack. LawZero’s core ideas—humble reasoning, verifiable knowledge, safety-conscious blockers—align with what many safety researchers now believe we need.
Unlike agentic systems that “pursue goals”, Scientist AI models the world, predicts behaviours, and acts as a moral co-pilot, not a pilot.
“We need a watchdog that doesn’t want power,” Bengio said in MIT Tech Review, June 2025.
Closing Thoughts
We’re entering a new epoch—not just of AI that does, but AI that decides. That shift calls for new forms of accountability, transparency, and evaluation. Efficiency will always matter, but safety in agency is the new currency of trust.
We need systems that aren’t just accurate—but aligned, interpretable, and honest about their uncertainty. In that future, it’s not about faster answers—it’s about answers we can live with.
If you’re building, regulating, or simply thinking about what AI should become, LawZero’s approach—and the frameworks discussed above—offer a meaningful way forward. Let’s not just audit AI outcomes. Let’s audit its soul.

Leave a comment